
What is Wrong with N50? How can we make it better? - part II
In our previous commentary, we discussed why N50 is a faulty measure of assembly quality. It can reward an aggressive assembler (or assembly strategy) that chooses one of many paths suggested by k-mers from repetitive regions to get high N50, but also higher number of incorrect junctions. The proposed solution was to augment N50 with another measure that compares expected k-mer distribution with observed k-mer distribution.
How does the measure work? In the first figure of this commentary, we presented the k-mer (k=21) distribution of a genome and showed that most 21-mers are present only once in the genome, a small number of 21-mers are present twice, and so on.
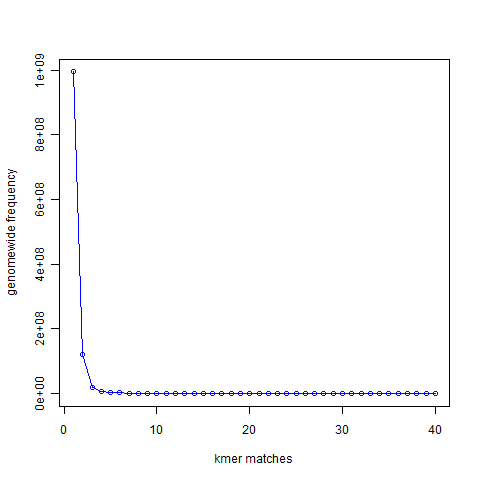{kind=link}
The second figure presented 21-mer distribution of simulated reads chosen from the same genome with the genome being sampled roughly 50 times. The peak representing unique 21-mers in the first figure moved to 40 in the second figure. The peak representing 21-mers present twice in the first figure moved to 80 and so on, because the reads were sampling the genome many times.
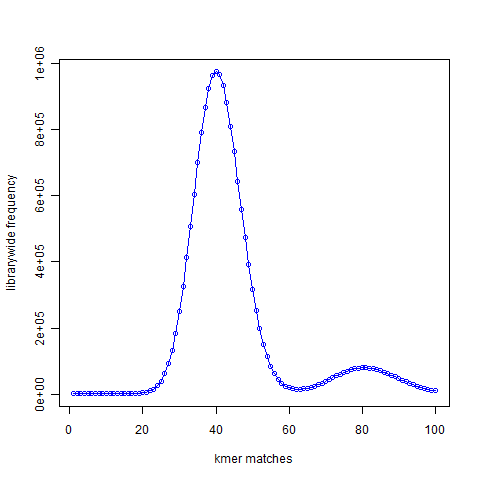{kind=link}
Given a set of NGS reads, the second figure is easy to construct. From the position of the peak at 40 (or at other region), it is possible to rank each k-mers as ‘unique’, ‘present twice’, ‘present thrice’, etc. That will represent the expected distribution of the k-mers.
Similarly, a version of the first figure is possible to construct from the de Bruijn graph-based assembly of the NGS library. From the assembly, it is possible to compute observed k-mer distribution of the corresponding k-mers.
If an assembly is correct, those two k-mer distributions should match as closely as possible. Therefore, any discrepancy reflects errors in the assembly. I can think of some exceptions in case of SNPs or haplotype differences, but for most genomes those factors come as as second order differences.
The readers may object that the above method does not directly address the question of incorrect junctions. That criticism is indeed true. However, if an assembler incorrectly connects contig A with B and C with D, whereas A should be connected to C and B with D, the assembler does not get high N50. It is possible to high N50 by an aggressive assembler, only if it traverses through the same repetitive region more often than reality and interconnects more contigs than reality.
Please let us know, whether you find any holes in the above argument.