
For Those Running Core Facilities (part 2)
For new readers, easiest way to follow us is through our twitter feed. The feed is updated, whenever we post a commentary here.
This is a continuation from our previous discussion on challenges in running core facilities related to next- generation sequencing and bioinformatic analysis. Many of the challenges are also faced by other bioinformaticians, ranging from individuals trying to analyze few large data sets to genome centers performing the same tasks at 1000x scale. The previous commentary focused primarily on infrastructure, and reader Rick Westerman made many valuable comments based on his experience. Today we will talk about the ‘real work’, by which I mean the task of converting millions of As, Ts, Gs and Cs into information relevant for biologists. When I say ‘real work’, I do not want to belittle the efforts of those setting up infrastructure, or helping in secure maintenance of data. However, the money flow in the system is guided by scientific discoveries. Best infrastructure helps in making great discoveries, but there are no guarantees.
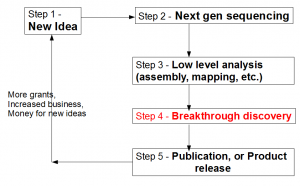
Let us view the entire loop (see figure above) from the viewpoint of a biologist. A biologist gets a novel idea (Step 1), and based on that, he contracts with a sequencing facility to sequence his samples. Sequencing center turns his sample into large library of A, T, G, Cs (Step 2). That sentence summarizes many complex steps, among which, sample preparation itself, can be quite challenging, especially for unusual experiments. Moreover, the efforts of sequencing facility are not straightforward by any means, because it has to keep abreast of changes in technologies, optimize protocols to get the highest throughput, get trained on latest protocols for unusual sequencing requests, upgrade software, and so on.
Step 3 requires converting the raw data into something more tractable. Typically, it involves mapping of reads on to a reference genome (if reference genome exists), or assembling of reads into larger units (contigs). This step is technologically very challenging due to the size of NGS data sets. The bioinformatician needs to filter reads for sequencing errors, try out various k-mer sizes, keep up with the latest analysis approaches, upgrade computers and RAMs for progressively larger libraries generated by new sequencing machines and so on.
What frustrates biologists the most is that even after three complex steps described above, they are no closer to the reward than months before. The next step - breakthrough discovery - is what ultimately makes their research visible and attracts funding for the efforts. For truly great discoveries, often the ‘pipeline’ shown above is not linear. The scientists need to understand the results from step 3, go back to do more sample preparation, sequencing and assembly (iterations of steps 1-3). However, when multiple rounds of sequencing are done, analysis process does not remain straightforward as described in step 3. Integration of data generated from different rounds/kinds of sequencing and finding their cross-correlation becomes more difficult than assembling one round of data set.
As a simple example, let us say a research group did one round of RNAseq on five tissues and assembled genes using Velvet+Oases. Based on their analysis of the reads, they decide to run another round of RNAseq and assemble using Trinity. Should the next assembly merge all reads (old and new) together, and generate new sets of genes? How to deal with previous Oases genes and all expression-related downstream analysis done on the old set? Portability of data requires mapping of all old information on to new releases of genes and genomes. Every iteration adds layers of complexities, because often integration of old data necessitates redoing old calculations. One may say that the above difficulties can be overcome by proper planning, but think about challenges posed by publication of new and powerful algorithm that allows a more refined analysis of existing data. Or what if a group performs transcriptome experiment of large number of RNA samples and another group publishes the underlying genome in the meanwhile? It is nearly impossible to prepare for all eventualities in such a fast-moving field.
The above discussion is from the point of view of biologists. Next, let us view the same process from a dedicated group of bioinformaticians involved in assisting biologists. They may be part of a sequencing core facility, or they may constitute of a separate group of experts. The conceptual problem they face is how much of the above tasks they should carry on their shoulder, and how much they should pass on to the individual biologists working on specific problems. We will divide the type of service provided into three categories, and discuss pros and cons of each category.
1. Basic Service
In this mode, the bioinformatics core facility helps in a set of early level processing of NGS data for a reasonable cost (such as $200/mapping). You can see one example of such pricing here. Then the researcher is on his own. He may have access to dedicated bioinformatician for an hourly fee.
The advantage of this mode (from the angle of core facility) is that the tasks are predictable and so that core facility can focus on optimizing a small set of highly repeatable activities. Disadvantage - the biologist needs to perform the real discovery process, and that may requires full knowledge of computational analysis of sequences. On the other hand, will someone knowledgeable about computational analysis even need the basic service?
2. Full Service
In this mode, the core facility works hand in hand with the biologist to guide him through the discovery process. For a core facility, the most challenging part of this mode is pricing, because discovery is somewhat open-ended. Should the core facility quote a fixed overall cost as part of a grant? Should it charge hourly fee and let the scientist figure out, how much service is needed? Only the first approach is workable for most real-life scenarios of full-service operations.
3. Hybrid Mode
If you followed my previous discussion, you have noticed that the figure shown above did not show a large box between step 3 and step 4, whose size is small for one simple experiment, but grows with many iterations of measurement. This box constitutes of maintenance and cross-correlation of various data sets generated by going back and forth between measurement and analysis. A core facility can commit itself to basic service (point 1 above) and assisting in data integration for a complex project. This is not ‘full service’, because the responsibility of making discoveries rests fully on the biologists. However, the tasks performed in hybrid mode goes way beyond analyzing individual libraries.
We apologize, if the above discussion appears somewhat abstract. It is a simplified description of our experience of working on many transcriptome- related research projects over the last decade. A large part of the time was dedicated to designing custom arrays and analyzing corresponding data. The other half of time was dedicated to NGS data sets. No matter what platform (array or sequencing) was chosen, the big picture did not change significantly from the above description.