
Big Data - Where Increasing Sample Size Adds More Errors
Conventional wisdom says larger sample size will make experiments more accurate, but that does not work in many situations. More samples can result in more errors, as explained by the following example.
Ask 1 million monkeys (~2^20) to predict the direction of the stock market for the year. At the end of the year, about 500K monkeys will be right and about 500K monkeys will be wrong. Remove the second group and redo the experiment for the second year. At the end of the year, you will be left with 250K monkeys, who correctly called the market for two years in a row. If you keep doing the same experiment for 20 years, you will be left with one monkey, who predicted the stock market correctly for 20 years in a row. Wow !

The above paragraph is taken from a youtube talk of best-selling author Rolf Dobeli, whose best-selling book appears to be a plagiarized version of N. N. Taleb’s writing. Taleb goes deeper into explaining the implication of the monkey experiment. Suppose you increase the sample size by asking 30x more monkeys about the stock market. At the end of twenty years, you will have 30 ‘smart’ monkeys instead of one. Now you have a large enough set to even search for that intelligence gene, which helps monkeys call the stock market correctly for 20 years in a row. A bigger wow !!!
Summarazing in Taleb’s words -
The winner-take-all effects in information space corresponds to more noise, less signal. In other words, the spurious dominates.
…
Information is convex to noise. The paradox is that increase in sample size magnifies the role of noise (or luck); it makes tail values even more extreme. There are some problems associated with big data and the increase of variable available for epidemiological and other “empirical” research.
You can read the rest of his chapter with all mathematical details here.

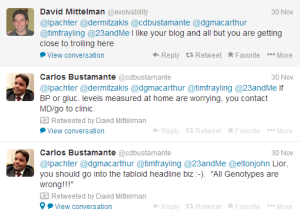
In another commentary along similar line, Lior Pachter wrote -
23andme Genotypes are all Wrong
The commentary is quite informative, but we will pick up one part that describes the ‘winner-take-all’ impact (or ‘loser-take-all’ in case of sickness) on users.
But the way people use 23andme is not to look at a single SNP of interest, but rather to scan the results from all SNPs to find out whether there is some genetic variant with large (negative) effect.
…..
Whereas a comprehensive exam at a doctors office might currently constitute a handful of tests a dozen or a few dozen at most a 23andme test assessing thousands of SNPs and hundreds of diseases/traits constitutes more diagnostic tests on an individual at one time than have previously been performed in a lifetime.
In plain English, suppose you walk into a doctor’s office and ask for your brain, heart, lungs, kidney, teeth, tongue, eye, nose and one hundred other body parts to be tested. Doctor comes back to you and reports that 107 out of 108 tests were within limit, but your kidney test reported some problems. The ‘winner-take-all’ impact will make you remember only the result that reported problem, even though more tests the doctor conducts, more likely he is to find a problem by random chance. Next you will go through more invasive tests of your kidney and maybe some hospital stay, making your body vulnerable in some other ways. Paraphrasing Taleb, the only way to legally murder a person is to assign him a personal doctor, who will keep monitoring (‘testing’) his health 24x7.
Presenting this well-known problem of multiple testing did not win Lior Pachter many friends. He was immediately called a ‘troll’ and other names by those with vested interests.
Calling people trolls, when they present different scientific argument, has become a new fashion. We have been through similar experiences, when we wrote a set of commentaries questioning the effectiveness of genome-wide association studies.
Battle over #GWAS: Ken Weiss Edition
Study History and Read Papers Written by Dinosaurs (#GWAS)
Genome Wide Association Studies (#GWAS) Are They Replicable?
Mick Watson immediately called us trolls and, and both he and Daniel MacArthur immediately blocked our twitter accounts from following them. Readers should note that it is one extra step of censoring, as explained below.
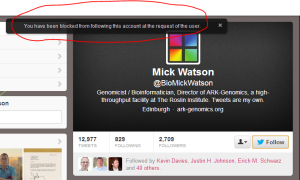
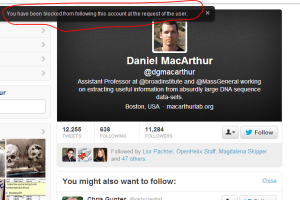
For those unfamiliar with Twitter, it is designed in such a way that you do not read things you are not interested to read. For example, we do not read what Kim Kardashian is doing every day by simply choosing not to follow her channel. So, why do these two gentlemen (‘open science advocates’) take the extra step of blocking us to follow them? It is done to make sure that our comments do not reach their audience, or is a form of twitter censoring. We wonder what they have to fear.

On the plus side, the above exchange got us familiar with the blog of Ken Weiss and co-authors (@ecodevoevo on twitter), which is very thoughtfully written and has become our daily read. Readers may enjoy their today’s commentary on big data in medicine.
The ‘Oz’ of medicine: look behind the curtain or caveat emptor!
They highlight six problems with the ‘big data’ approach. The following list is only an abbreviated version of their very detailed commentary.
Problem 1: Risks are estimated retrospectively–from the past experience of sampled individuals, whether in a properly focused study or in a Big Data extravaganza. But risks are only useful prospectively: that is, about what will happen to you in your future, not about what already happened to somebody else (which, of course, we already know).
Problem 2: We are usually not actually applying any serious form of ‘theory’ to the model or to the results. We are just searching for non-random associations (correlations) that may be just chance, may be due to the measured factor, or may be due to some other confounding but unmeasured factors.
Problem 3: Statistical analysis is based on probability concepts, which in turn are (a) based on ideas of repeatability, like coin flipping, and (b) that the probabilities can be accurately estimated. But people, not to mention their environments, are not replicable entities (not even ‘identical’ twins).
Problem 4: Competing causes inevitably gum up the works. Your risk of a heart attack depends on your risk of completely unrelated causes, like car crashes, drug overdoses, gun violence, cancer or diabetes, etc.
Problem 5: Theory in physics is in many ways the historic precedent on which we base our thinking……But life is not replicable in that way.
Problem 6: Big Data is proposed as the appropriate approach, not a focused hypothesis test. Big Data are uncritical data–by policy! This raises all sorts of issues such as nature of sample and accuracy of measurements (of genotypes and of phenotypes).