
Big Data and Buzzword-driven Science
Imagine chaos theory became popular to catch the attention of VCs and Federal grant agencies and they gave ‘angel’ money to kids for throwing rocks on neighbors’ glasses, funded projects to increase school shooting and doubled military’s drone budget for creating chaos around the world. Or imagine government locks up all ENCODE-deniers using terrorism law, because their refusal to accept functionality of 80% of human genome and incessant complaints terrorize good scientists doing God’s work. Bastardization of technical terms has become very common these days and ‘big data’ is the latest example.
In this commentary, we will explain where the technical term ‘big data’ came from by walking you through the history of internet. First enjoy this youtube video (WARNING - stay away, if F-words bother you).
If you did not understand what they were passionately arguing about, do not worry. That is how technical discussion work. Either you face the technical problem in your daily work and appreciate the solution, or you do not. The video showed what ‘big data’ was during the first 15 years of its 17 year history until shysters found the words cool.
‘Big data’ did not imply hard-drive full of data, or doing biology without going to bench. It was about solving a specific problem related to setting up internet websites and web-business. Following cartoon shows how a website works at a very crude level.
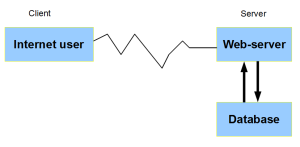
When internet companies started in the mid-90s, they had to work with existing computing models - namely ‘client-server’ and ‘SQL database’. The concoction was not designed for internet. SQL databases were traditionally used for banks holding hundreds of customer accounts, and big companies holding employee and payroll information. Using the model for internet posed two problems.
(i) Neither banks were accustomed to spammers opening new accounts every few seconds, nor big corporations hired new employees at the blink of an eye. Rapid growth in database size to terabytes or more was not provisioned for in the existing model.
(ii) Even bigger issue was the following. Unlike banks, internet companies were in the business of experimenting with their data. They needed to redesign the sites, modify codes, add fields to database, and so on. The programmers using data were quite powerful and were always in conflict with those managing the databases. The main problem was that SQL method of describing the data in SQL databases was not compatible with object-oriented way of processing data in programs (described as ‘impedance mismatch’).
We are not talking about simple conflict, because some commentators went to describe the proposed solution (ActiveRecords in Ruby on Rails and other ORM) as ‘Vietnam of computer science’.
The Vietnam of Computer Science
(Two years ago, at Microsoft’s TechEd in San Diego, I was involved in a conversation at an after-conference event with Harry Pierson and Clemens Vasters, and as is typical when the three of us get together, architectural topics were at the forefront of our discussions. An crowd gathered around us, and it turned into an impromptu birds-of-a-feather session. The subject of object/relational mapping technologies came up, and it was there and then that I first coined the phrase, “Object/relational mapping is the Vietnam of Computer Science”. In the intervening time, I’ve received numerous requests to flesh out the discussion behind that statement, and given Microsoft’s recent announcement regarding “entity support” in ADO.NET 3.0 and the acceptance of the Java Persistence API as a replacement for both EJB Entity Beans and JDO, it seemed time to do exactly that.)
Thoughts on Vietnam commentary
Some internet companies realized that getting rid of SQL database (and more importantly associated SQL programmers) was the best solution, and they came up with new set of scheme to store and process unstructured data related to web-businesses. They had to design methods for rapidly processing the data, new ways to search through the data and so on, because old techniques implemented within SQL databases were not useful any more. The collection of all those techniques were called ‘big data’.
Fast forward to 2013, when government decides to allocate 100 million dollars for ‘big data’ science. How does buzzword-driven science work? If you call the NIH grant-manager and ask for definition, he will most likely tell you that the term is defined broadly and encourage you to submit a proposal. As long as you have the word ‘big’ somewhere in the proposal and ‘data’ somewhere in the proposal, you are in.
How do those proposals get judged? If you can create a buzz and associate your name with ‘big data’, you will be the winner of government money. To do that, you will need to arrange ‘big data in biology’ conferences, use blog and twitter to explain how you are ‘THE BIG DATA SCIENTIST’ and, even better, spend some time creating nice dumbed-down videos like the following one.
Yes, it is hard work, but the payoff in free taxpayer money is big too. When the project is over, make sure you arrange another press conference to claim that you changed biology textbooks. Contrast that with ‘big data’ for web businesses, where a real long-standing problem was solved and got paid by gain in business productivity.
Doing biology through analysis of genome-wide data on a ‘dry bench’ is nothing new, and another pair of buzzwords - ‘systems biology’ was coined 12 years back to describe such approach. Let us not allow those inconvenient facts obstruct ambitious projects saving us from world’s troubles.