
Evolution, not Hadoop, is the Biggest Missing Block in Bioinformatics
A Biostar discussion started with -
Uri Laserson from Cloudera:
“Computational Biologist are reinventing the wheel for big data biology analysis, e.g. Cram = column storage, Galaxy = workflow sheduler, GATK = scatter gather. Genomics is not special.” “HPC is not a good match for biology since it HPC is about compute and Biology is about DATA”.
http://www.slideshare.net//genomics-is-not-special-towards
Uri might be biased because of his employer and background but I do think he has a point. It keeps amazing me that the EBI’s and Sangers of this world are looking for more Perl programmers to build technology from the 2000’s instead of hiring Google or Facebook level talents to create technology of the 2020’s using the same technology Google or Facebook are using.
In 2010, we were stuck with several big assembly problems (big for those days) and associated biological questions. For assembly, Hadoop was the first thing we looked into and long-time readers may remember that Hadoop-related posts were among the first topics in our blog. Like the above author, we also expected to revolutionize biology by using technology of Google/Facebook.
Using Hadoop for Transcriptomics
Contrail A de Bruijn Genome Assembler that uses Hadoop
Over time, we realized that Hadoop was not the right technology for assembling sequences. For assembly, one has a fixed final product and the goal of the algorithm is to combine pieces to get there. There are faster and more economic ways to solve that problem even using commodity hardware, and Hadoop did not turn out to be our best option. We already covered many of those efficient algorithms in our blog.
Today’s discussion is not about assembly but on the second and larger problem
- figuring out the biology and whether big data can help. Figuring out of the biology is the final goal of all kinds of computational analysis, but increasingly that notion seems to get forgotten. This point has been highlighted by a comment by Joe Cornish in the original biostar thread, but let us elaborate based on our experiences.
-——————————————————
Is human being like a computer program?
Two decades of publicity about human genome and genomic medicine made people think that human beings work like computer programs. To them, the genome has the software code or ‘blueprint’ and by changing that code, every aspect of a person can be changed. A culmination of that one-dimensional focus of genome results in junk papers like the following, where the authors try to find genomic code for romantic relations.
The association between romantic relationship status and 5-HT1A gene in young adults
Individuals with the CG/GG genotype were more likely to be single than individuals with the CC genotype.
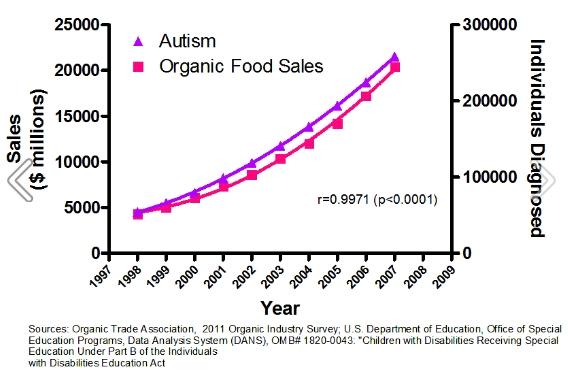
What gets forgotten is that a person is more like an analog machine built from cells, where all kinds of chemicals work together to give it functions like digesting food, walking, maintaining body temperature and pursuing romantic relationships. The genome only provides the informational content, but until a researches shows the causal mechanism between a genome-based association and actual workings of the biochemical components, a genome-based association is just a statistical observation. Speaking of statistical observations, the following one shared by @giggs_boson looks pretty good.
-————————————————————-
Is human being like a car then?
A car consumes fuel, moves around, can maintain the inside temperature and can even pursue romantic relationships in Pixar movies. Jokes apart, is a human being like a car or other machines?
One would immediately point out that the cars need human drivers, but that is not true with modern robot-driven cars. Another objection is that the cars do not spawn out new cars by themselves, whereas self-reproduction is the main difference between living beings and modern sophisticated machines. We can work around that objection by doing a ‘thought experiment’, where we put a robot inside a car with a sophisticated digital printer and code to produce all kinds of car parts by taking raw materials from outside. Once ready, the robot inside pushes the parts out and another robot attached to the exterior assembles them into a new car. Is the car-robot combination like a living being?
-————————————————————-
There is another level of complexity
Even though they do not tell you, many researches working on human medicine follow the car-robot mechanical model of living beings. That is not without reason, because the mechanical model worked very well in 20th century medicine. It has been possible to replace limbs with artificial ones (analogous to changing flat tires?), controlling hearts with pacemakers (‘rebuilding engine?’), fighting off invaders with chemicals and even doing brain surgery by using a mechanical view of the system, where the surgeon is a highly-skilled mechanic.
However, the mechanical view fails completely, when researchers try to understand the human genome or any genome for that matter. Here is the biggest difference between living beings and the replicating car+robot combination described above. The living organisms, unlike the replicating car+robot combination, is self-built. The system constructed itself from absolutely nothing through an iterative process lasting for 3-4 billion years, and many traces of that evolutionary process can be determined from (i) fossil records, (ii) comparing cell structures and biochemistry of different living organisms and (iii) comparing informational contents (genomes and genes) of the same organisms.
By staying focused on only one or two of those three aspects, a researcher can severely handicap himself from getting the full picture. A human genome has ~20,000 protein-coding genes and some of them code for functional blocks, which stabilized in the earliest bacteria ~3 billion years back, some of them stabilized in earliest eukaryotes over 2.5 billion years back and some are more recent. The only way to understand each functional block is to compare organisms, which took different paths since their divergence. That means using different models for different groups of genes. This kind of comparative analysis is often missing from most analysis.
Going back to the original point, adding evolutionary context with genomic, biochemical and developmental data is the biggest challenge and missing block from bioinformatics, not the availability of computing power or programs to analyze bigger data sets. The experimental biologists, out of necessity, focus on one organism (one machine), because it is impossible to maintain a lab with ten different species. Bioinformaticians, on the other hand, are free to compare and analyze, but quite a bit of that analysis requires thinking about functions, development and evolution of the entire machines (living organisms) rather than only the genomes, but that is often missing from the bioinformatics literature. Those, who do it, isolated themselves into the subfield of evolutionary molecular biology.

In a small and insignificant way, we tried to do the entire exercise in our electric fish paper and found it quite challenging. At first, we started with genome assembly of electric eel, but realized that the genome was not very useful to infer about functionality of the electric organ. We also compared RNAseq data from electric organ, muscle and other organs of electric eel. RNAseq data adds a bit more functional information beyond the genome, but it is still limited to one organism. Then we decided to compare RNAseq data from different electric fish species, which evolved electric organs independently and that added the evolutionary context to the whole picture.
Our entire exercise greatly narrowed down the list of genes on which biologists can further do their lab tests. We also worked on theoretically connecting those genes based on their known functions, and these connections can be used as hypotheses to direct the lab tests. This last part (connecting the dots through a narrative) is nearly impossible to do with software, but even if one can do that, there is another level of difficulty. The narrative needs to be updated iteratively based on small-scale experiments and additional data. Which experiments to do to challenge the story is a scientific process and we do not believe any software can replace the process.
Long story short, computational biologists need to solve real puzzles consisting of determining of functional or disease mechanisms, and then build tools based on a handful of successful paths. The current approach of focusing on human genomes and throwing all kinds of data and statistical tools (GWAS) in the hope of discovering disease mechanisms (or romantic partners) is too limited and wasteful.