
Seattle Sequencing Meetup with Bina Technologies


Every month, Aubree Hoover and Roger Bumgarner arrange a Meetup in Seattle for those interested in sequencing technologies. The presenters come from both universities and industry, and we always found the talks and the post-talk discussions to be very informative. Previously, we covered the Meetup presentation by Jay Shendure (here and here).
Last month, Dr. Gianfranco de Feo flew here from SF bay areas to present on ‘bina analytics’. Bina Technologies is a startup company developing bioinformatics analysis platform for next- generation sequencing (yes, ‘next-gen’ with an apology to @assemblathon). We have always been curious about what value these bioinformatics companies provide, and found the talk to be fairly informative in that regard. Dr. de Feo was kind enough to share his slides with us, which you can view below. Our very personal and opinionated comments follow.
Slides
What we learned
Please note that the following comments are not entirely from the talk and contains our own interpretations in some places.
a) Company
Bina is a multi-cultural and multi-lingual company. The name of the company is from Persian language, because of the roots of the founder/investors. The name means insight/knowledge in Hebrew/Persian, but also refers to a musical instrument in India.

The company employs about 20 highly skilled young techies.
b) Technology
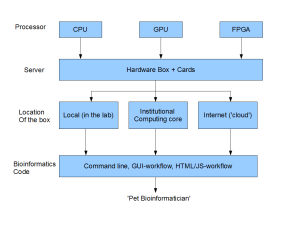
The above figure not about Bina Technologies, but a generalized description of entire technological stack for a bioinformatics analysis pipeline. At the ‘lowest’ level, you need the hardware and that hardware can be CPU (Intel, ARM), GPU, FPGA or combination of multiple chips. Also count in the hard-disk (HDD vs SSD), RAM and other options. Those chips and cards need to be assembled in the form of a box, which the user purchases. The box needs to be placed somewhere and that ‘somewhere’ can be right in your basement or in someone else’s (Amazon) house. On top of all comes the software programs - aligners, assemblers, etc. Finally add the ‘lonely pet bioinformatician’ and you are done.
The following figure provides a description of Bina’s approach to the problem. They build a box for you (64-core CPU + 512G RAM), install the necessary software and provides nice workflows with graphical interfaces to make the life of pet bioinformatician easy.
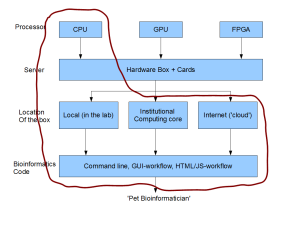
The location of the box is likely to be local, but they have some ‘cloud- enhanced’ workflows. For example, their annotation tools are currently in the cloud, and they will bring those to the boxes later.
c) Bioinformatics Stack
The details are all provided in the slides, but these are the ones we remember off-hand.
i) Aligners for Variant Calling - They installed ‘Bina aligner’ (seqalto) and BWA. They also did extensive benchmarking for GATK.
ii) Aligners for RNAseq - Bowtie + Tophat + Cufflinks.
iii) PacBio - They installed LSC for error-correction.
They have done extensive bench-marking and most installed programs. One interesting finding was that they did not see major difference between GATK 1.6 and GATK 2.7 in terms of SNP accuracy. That distinction is important for many users, who are concerned about the cost, because GATK1.X is free and GATK 2+ is not (check Sanger Dropping Broads GATK after License Change).

d) Business Model
We are reproducing them verbatim from the notes. More details are available in the attached slides.
i) Bina-on-demand
pay as you go - no fixed monthly fee
allows for access by multiple groups/ aggregate demand
no hardware purchase
ii) Bina subscription
annual subscription option
Low/medium/high throughput pricing levels available
no hardware purchase
iii) Bina custom
customized analysis and data management platforms
design, deploy and operational phases
multi-year projects w/evolving requirements
e) Thoughts about the Business
We did a quick calculation and computed the cash outflow for 20 employees to be ~ 20*$150K = $3M/year. Is $150K/person typical? Previously, we did similar analysis for PacBio, JGI and Illumina based on more realistic numbers and got the following estimates.
The company is burning 80 million dollars every year at the latest quarterly run rate. With 342 employees, that is $234K per employee. I compared the numbers to JGIs, and Alex Copelands talk was helpful in giving us the number. At $65 million/year and 250 employees, JGIs run rate is $260K/employee. Illumina, at $652 million for 2400 employees, is in the same ballpark $272K/employee. You need to keep in mind that the numbers include the costs of reagents, chemicals and instruments purchased by the organizations, but those expenses are finally decided by the employees, isnt it? What I took from the above back-of-the-envelop analysis is that PacBio is not indulging on employee parties.
Those estimates for PacBio, JGI and Illumina included reagents and therefore the rent+salary component was lower. For Bina to be successful, they will have to generate ~$3M of excess cash inflow/year beyond the cost of the box itself. That excess cash-flow needs to come from the excess value provided by the workflows, because otherwise the customers have the options of installing the programs (Bowtie, BWA, GATK) themselves.
It is too early to say how successful the model would be and, moreover, the success partly depends on other bioinformatics companies, including BGI, competing in the same space. We will closely monitor related companies and keep our readers posted.