
Protests about HeLa Sequencing, Research Crowdsourcing and Other News of the
1. A paper titled The Genomic and Transcriptomic Landscape of a HeLa Cell Li ne published today seem to have made many researchers upset.
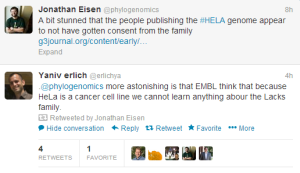
Do you share the concerns, or do you think HeLa is so central to all cancer research that the concerns are somewhat overblown?
-———————————
2. Interesting commentary from phylogenomics blog
Diabetes & H.pylori - a correlation but no known causation despite authors claims
-———————————-
[The following write-up is modified based on our discussions with Titus. You can follow them in the comment section of his blog.]
3. Titus Brown plans to crowd-source research and get it out of the hands of academia. It is high time.
Does anyone want to work on a hard research problem?
The Crazy Idea
I have a few really hard data analysis problems to solve. One of them, infinite metagenome assembly, is reasonably nicely encapsulated and bounded, and presents some interesting parallelism and data structure challenges. Moreover, we (me, my lab, and my collaborators) have lots of sample data and understand the basic problem pretty well. I submitted a grant on it, but in part because of straight up research funding challenges, and also because of the sequester, I’m unlikely to get the grant. But we still need to solve the problem. I’ve been thinking of working on it myself, but I’m increasingly unable to put in the time.
What if I crowdsourced the problem?
More specifically, what if I issued an open call for people to come “play” with us on this problem? I could set up a mailing list and an editable community doc project, as well as a repo with sample data sets and scripts and code (this is already available but not necessarily easy to work with). The goal would be to come up with a more detailed understanding of the problem, whatever novel data structures and algorithms that were needed, an implementation at scale, and a practical engineering solution with empirically shown “good” scaling behavior.
Here is the reward.
People who worked closely with me and my group would, at the least, be co- authors on any publication that arose, and the git repo history and mailing list would serve as a history of intellectual and technical provenance.
I think it is a fascinating idea. We had some quips about potential IP claims from the university, and you can follow those discussions here. For example, let us say an outside collaborator comes up with a Google Pagerank-type algorithm with significant commercial value unrelated to the direct research problem. If the collaborator wants to commercialize it, will he have to deal with the University? Titus says that will not be the case, because there is no contract. What if the outside collaborator borrows and refines an idea suggested by Titus? Can he get a patent not shared with Titus? That does not seem fair to Titus, and there must be an implied contract (or other legal framework) governing such conflicts.
Another alternative Titus suggested is making discoveries non-patentable, but the project needs to be supported somehow for the core team to continue working on it. The only other potential financial mechanisms are government grants or wealthy donors. US government grant will not be a viable path in the long-run, but the second option may work.
-——————————–
4. Mick Watson writes an excellent commentary titled -
The alternative what it takes to be a bioinformatician
So, here is the alternative version of what it takes to be a bioinformatician:
Patience.
Suspicion.
Social skills.
Big cojones.
The mind of a super sleuth.
Delivery.
The ability to code.
Please follow his link for more details.