
A Bird's Eye View of NCBI GEO Database
NCBI GEO database is the world’s largest public online repository for transcriptome datasets. It includes transcriptome data from several types of experiments arrays, next-gen sequencing, MPSS, SAGE, RT-PCR, etc., although major share of data comes from array measurements. For short read datasets (NGS), some researchers prefer to use NCBI SRA database as a repository. SRA database includes both transcriptomic and genomic sequences, and we will cover its transcriptomic component in a later post.
Majority of GEO users typically download and analyze only one or two measurement sets related to their own research. Here we plan to look at the entire collection of measurements stored in GEO. This post is introductory, but over the next few days, we will present various interesting charts of GEO data to show trends in transcriptomics.
For non-users, let me first explain the structure of GEO. If you go to GEO website, you will notice the following stats on the right-hand corner near the top. They show the current contents of the GEO database.
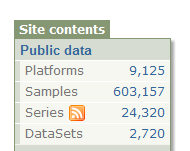
GEO data sets are categorized in terms of platforms and series. What are platforms and series? Short answer -
**each unique array design is a platform
each hybridization on an array is a sample
entire collection of several array measurements for a research project is a series**
Let me now give a long answer using few examples.
Suppose you purchased a batch of 10 Affymetrix human gene-chip arrays (all identical) and hybridized them with samples from kidney tissues of 10 individuals (one sample/array). When you report the data to GEO database, NCBI saves them in two ways.
Firstly, it creates a file containing i) description of array probes for the array used by you (platform), and ii) 10 measurement sets from you. Each measurement set consists of hybridization numbers for all array probes. This combined file is called a GEO Series file and its name starts with GSE, such as GSE111, GSE1234, etc.
In another format, NCBI puts together all experiments by all groups around the world using the same version of Affymetrix human gene-chip array. This is GEO Platform file, and its name starts with GPL, such as GPL1234, GPL431, etc. Please note that GPL431 is not the same as GSE431. Anyone downloading a complete platform file will not only access your data, but also data from others using the same array.
As another example, let us say you designed 10 tiling arrays spanning an entire insect genome and hybridized each array once with pooled cDNA from various tissues of the insect. This time, your experiment consists of multiple platforms each covering part of the insect genome. Therefore, your series file consisting of data from the entire experiment includes 10 platforms and samples, whereas each platform file contains design of a single array and its associated data. An user will be better served by downloading the series file for your experiment (GSE) than platform files.
As of today, GEO contains 9125 platforms and 24320 series. That means 24320 different experiments had been submitted to GEO since big bang. The number of platforms is lower than number of series, because some popular designs are used 2,3,5 or even 100 times. In fact, the redundancy is higher than what the ratio of above two numbers (14320/9125) suggests, because many platforms are empty. They were submitted by commercial companies in anticipation of future use. We will see, which designs are the most popular, in a later commentary.
In the following posts, we will go through the entire collection of GEO data sets, and learn about types of transcriptome experiments being performed by biologists around the globe.